[قواعد كتابه عربينا نابعه من اهداف واولويات مفصله في مقالات سابقه]
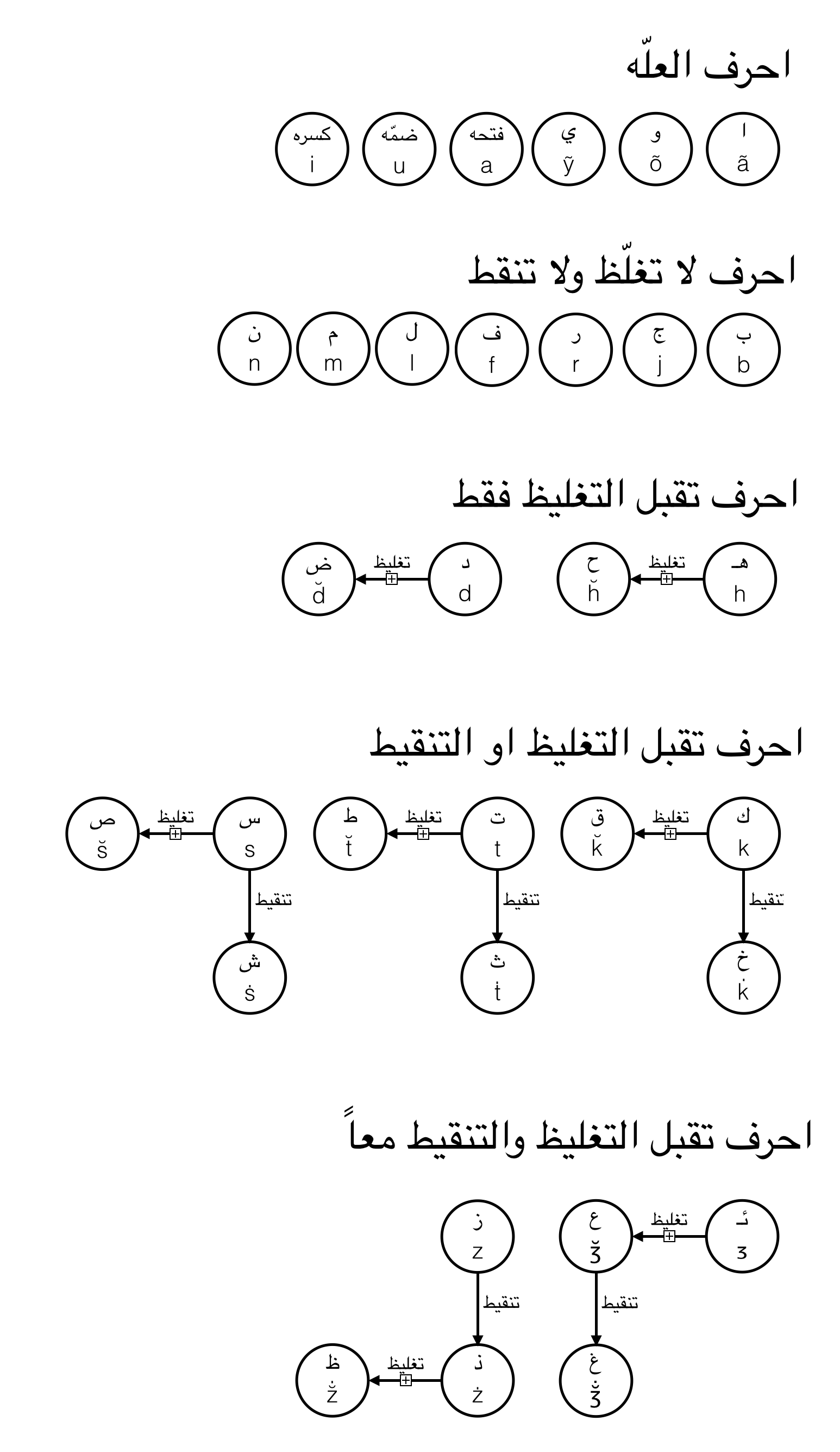
نختم اليوم الحديث عن صياغه احرف مغلّظه واخرى منقّطه من احرف لاتينيه “اساسيّه” في كتابه عربينا. فبعد القواعد المفصّله في المقالات الثلاثه السابقه، لم يبق من احرف العربيه التقليديه سوى ثلاثه احرف لم نعرّف لها بديلا في عربينا، وهي:
| السبب | سنعتبره | الحرف العربي |
|---|---|---|
|
مشابهه شكل الهمزه في عربينا {ᴣ} لشكل العين التقليدي، وارتباط العين بلفظ “همزه غليظه” في ذهن القاريء غير العربي علي -> Ali = ء ل ي |
همزه مغلّظه |
ع |
| النقطه فوق الغين في الكتابه التقليديه في ذهن القاريء العربي، وكون لفظ الغين يستدعي حرف h في ذهن القاريء غير العربي غسان -> Ghassan |
عين منقوطه |
غ |
| ارتباط الظاء بلفظ “ذ غليظه” في ذهن القاريء غير العربي
ظرف ـ> Tharf = ذ ر ف |
ذ مغلّظه |
ظ |
واستعمال الهمزه لبناء حرفي العين والغين قد لا يكون بديهيا للقاريء العربي، ولكنه سهل التعلّم على اي حال كون رسم الهمزه في عربينا {ᴣ} قريبا نوعا ما من حرف عين معكوس. وللزياده في التسهيل، فإن عربينا تستعمل كأساس لحرفي العين والغين نوعا آخر من حرف {ezh} اللاتيني هو مماثل شكلا ولكن اكبر حجما، لكي يتناسب الفرق في حجم {ᴣ ʒ} مع الفرق في حجم الهمزه والعين في الكتابه التقليديه {ء ع}.
| Unicode Block | URL Escape Code | HTML Entity | Unicode Name | Unicode Code Point |
Glyph |
|---|---|---|---|---|---|
| IPA Extensions | %CA%92 | ʒ | Latin Small Letter Ezh | U+0292 | ʒ |
| Phonetic Extensions | %E1%B4%A3 | ᴣ | Latin letter small capital ezh | U+1D23 | ᴣ |
وبهذا تصبح لدينا في عربينا احرف ثلاثه جديده:
| Unicode Code Point |
Glyph | فنستعيض عنه باستخدام | نعتبره | الحرف العربي |
|---|---|---|---|---|
| U+0292 U+0306 |
ʒ̆ | ʒ + ̆ | ء مغلّظه | ع |
| U+0292 U+0310 |
ʒ̐ | ʒ̆ + ̇ |
ع منقطه | غ |
| U+007A U+0310 |
z̐ | ż + ̆ | ذ مغلّظه | ظ |
ملاحظه مهمّه
لاحظ ان حرف الغين وحرف الظاء كلاهما يجمع بين علامه التغليظ وعلامه التنقيط.
فالظاء مثلا عباره عن “ذال مغلظه”، والذال عباره عن “زين منقوطه”. او بعباره اقصر، فحرف الظاء يمكن اعتباره “زين منقوطه مغلّظه”، ولذلك يُبنى على الحرف اللاتيني z عن طريق اضافه علامه التغليظ {breve} مع علامه التنقيط {dot}. ومع ان هاتين علامتان منفصلتان نظريا، الا ان الاسهل تقنيا هو اضافه علامه فارقه واحده فوق حرف z هي علامه {Candarabindu} والتي تجمع بين رسم هلال التغليظ ونقطه فوقه:
| Unicode Block | URL Escape Code | HTML Entity | Unicode Name | Unicode Code Point |
Glyph |
|---|---|---|---|---|---|
| Combining Diacritical Marks | %CC%90 | ̐ | Combining Candrabindu | U+0310 | ̐ |
ملخص احرف عربينا حتى الان
امثله
| ʒ̆alãᴣ | علاء | ʒ̆alỹ | علي |
| maʒ̐õl | مغول | ʒ̐arb | غرب |
| maʒ̐rib | مغرب | maʒ̆mõl | معمول |
| z̐alãm | ظلام | z̐unõn | ظنون |
| ʒ̆as̆ỹb | عصيب | ʒ̐alỹz̐ | غليظ |
| z̐alỹl | ظليل | żalỹl | ذليل |
| salỹb | سليب | zulãl | زلال |
| s̆alỹb | صليب | ʒ̆ażab | عذاب |
ملاحظات للمختصين فقط
- The diacritical marks used above are significantly different from traditional Arabic tashkil diacritics (ُ,ِ ,َ ) in that the latter ones operate on the same alphabetic letters in order to specify different succeeding vowel sounds, while the breve and dot introduced here operate on a base grapheme in order to produce a new, entirely different letter in the alphabet. For more details refer to this article on combining marks in Unicode.
- The use of diacritical marks as shown above introduces an application layer complication. There is now a need to perform Unicode normalization on all input text, taking precomposed Unicode codepoints back to their decomposed equivalents. This is necessary to ensure that text that renders in the same way is also encoded into the same Unicode sequence. For example, the string “ʒ̐arb” which is the Arabic word for sheep could be coded in multiple ways that render into the same graphemes visually. Such as:
- “ʒ̐arb” (U+0292 U+0310 U+0061 U+0072 U+0062)
- “ʒ̐arb” (U+0292 U+0306 U+0307 U+0061 U+0072 U+0062 )
- This complication is unavoidable as it is not possible to control the encoding of graphemes from within the language specification itself. Luckily (or should it read unfortunately?) this complication is suffered commonly by many other scripts, resulting in well established practices for normalizing Unicode at the application layer. For more information a good place to start is this Wikipedia article on the subject.
